I Akademickie Mistrzostwa Geoinformatyczne – GIS Challenge 2017
W dniach 10–12 maja 2017 roku w Lublinie po raz pierwszy w Polsce odbyły się Akademickie Mistrzostwa Geoinformatyczne – GIS Challenge. Inicjatorem i głównym organizatorem wydarzenia był Wydział Nauk o Ziemi i Gospodarki Przestrzennej UMCS, a współorganizatorami 16 uczelni z całej Polski oraz stowarzyszeń naukowych, działających m.in. na rzecz geoinformatyki.
GIS Challenge w liczbach
W GIS Challenge 2017 wzięło udział 97 studentów tworzących 35 zespołów. Reprezentowali oni 7 różnych kierunków studiów (Geoinformatyka, Geoinformacja, Geografia, Geodezja i Kartografia, Geodezja i Technologie Informatyczne, Gospodarka Przestrzenna i Ochrona Środowiska) oraz 16 uczelni wyższych z 10 miast Polski: Katowic, Krakowa, Lublina, Łodzi, Poznania, Olsztyna, Szczecina, Torunia, Warszawy i Wrocławia. Najwięcej uczestników przyjechało z Warszawy (10 zespołów z 4 uczelni), Wrocławia (6 zespołów z 3 uczelni) i Krakowa (5 zespołów z 2 uczelni). W ścisłym finale znalazło się 28 uczestników (10 zespołów) z 8 ośrodków akademickich. Pierwsze 3 miejsca przypadły reprezentantom Politechniki Wrocławskiej, Uniwersytetu Przyrodniczemu we Wrocławiu oraz Uniwersytetu Marii Curie-Skłodowskiej w Lublinie.
Zadania GIS Challenge
Zadania, jakie pojawiały się na GIS Challenge 2017 zostały przygotowane przez współorganizatorów. Opracowała je grupa kilkunastu osób, z których każda była odpowiedzialna za 2 zadnia (poziom eliminacji i finał). Spośród autorów zadań organizatorzy zaprosili do Komisji Sędziowskiej 10 osób.
W trakcie eliminacji uczestnicy mistrzostw przesłali 199 propozycji rozwiązań, z czego tylko 114 było poprawnych. W wyniku tego skuteczność rozwiązywania zadań była na poziomie 57%. Z kolei w finale drużyny przesłały 67 propozycji rozwiązań, z których 31 było poprawnych. Skuteczność rozwiązywania zadań w finale wyniosła 46%.
Z zadań przygotowanych do etapu eliminacji tylko jedno nie zostało rozwiązane, natomiast w finale uczestnicy nie rozwiązali aż 4. Najtrudniejsze okazały się zadania związane z przetwarzaniem danych rastrowych oraz układami współrzędnych, natomiast najłatwiejsze były te, które dotyczyły narzędzi geoprocessingu oraz operacji na tabeli atrybutów.
Rozwiązania zadania
Szczegółowa treść zadań I Akademickich Mistrzostw Geoinformatycznych – GIS Challenge 2017 zamieszczona jest na stronie http://gischallenge.com/ w zakładce Informacje ogólne → Zadania 2017.
Do prezentacji sposobu rozwiązań wybrano zadania: nie rozwiązane, pomimo podejmowanych prób (zadanie nr 6 − eliminacje, zadanie nr 5 − finał), o największej liczbie podejmowanych prób (zadanie nr 7 − eliminacje) oraz o największej skuteczności rozwiązywania (zadanie nr 4 − eliminacje).
Propozycja rozwiązania zadań z wykorzystaniem oprogramowania ArcGIS oraz Microsoft Office.
Zadanie nr 6
- Należy utworzyć nowy LAS Dataset korzystając z np. z narzędzi ArcToolboc; Data Management Tools → LAS Dataset → Create LAS Dataset.
- Dodać do niego dwa wejściowe pliki LAS: Data Management Tools > LAS Dataset > Add Files to LAS Dataset.
- Z okna Catalog wyświetlić własności (Properties) LAS Dataset: obliczyć statystyki danych, wybierając ”…” w kolumnie Statistics, a następnie Calculate.
- Zapoznać się z tabelami statystyk: Returns, Attributes, Classification Codes.
- Utworzyć DTM (LAS Dataset to Raster): nałożyć filtr na chmurę punktów, tak aby wykorzystać tylko punkty klasy Ground, reprezentujące powierzchnię terenu wykorzystać wszystkie odbicia, do wynikowego rastra przypisać średnią wartość wysokości (Elevation).
- Utworzyć DSM (LAS Dataset to Raster): nałożyć filtr na chmurę punktów, tak aby wykorzystać punkty klasy Ground i High Vegetation, wykorzystać wszystkie odbicia, do wynikowego rastra przypisać średnią wartość wysokości (Elevation).
- Obliczyć nDSM poprzez odjęcie DSM – DTM, za pomocą narzędzia Spatial Analyst Tools → Map Algebra → Raster Calculator.
- Usunąć błędne wartości < 0, które mogą wynikać z błędów w klasyfikacji danych (jeśli „DSM – DTM < 0”, to należy przypisać „0” korzystając z narzędzia Con)
- Obliczyć średnią wartość wysokości w każdym poligonie warstwy shp używając narzędzia Spatial Analyst Tools → Zonal → Zonal Statistics; opcja MEAN
- Zmienić symbolizację rastra na Unique Values i wskazać poligon o największej wartości.
Zadanie nr 7
Zadanie rozwiązać można korzystając tylko z danych pochodzących z Banku Danych Lokalnych (BDL) (https://bdl.stat.gov.pl), które są opisane kodem TERYT.
Chcąc wskazać gminy spełniające wymagane w zadaniu warunki należy kolejno w BDL zaznaczać:
- Dane według dziedzin→Urodzenia i zgony→Urodzenia żywe, zgony i przyrost naturalny na 1000 ludności.
- W następnym oknie należy odhaczyć opcje „2015” oraz „przyrost naturalny na 1000 ludności”. W kolejnym oknie należy upewnić się, że wybrana jest opcja Układ wg TERYT i przejść do sekcji „Zaznacz”, gdzie w zakładce „Zaznacz gminy” należy wybierać: „gminy miejskie (1), gminy wiejskie (2), gminy miejsko-wiejskie (3)” i przenieś je do wybranych (2478 gmin). W następnym kroku należy wyeksportować dane do Excela wybierając Export → XLS tablica wielowymiarowa. Bezpośrednio w Excelu w nowej kolumnie należy użyć formuły formatowania warunkowego JEŻELI, sprawdzającej, czy wartość przyrostu jest > 0. Jeśli warunek jest spełniony należy przypisać „1”, a jeśli nie „0”.
- Dane według dziedzin→Stan ludności→Ludność wg grup wieku i płci. Tutaj należy powtórzyć procedurę opisaną powyżej. Bezpośrednio w Excelu w nowej kolumnie należy użyć formuły formatowania warunkowego „JEŻELI”, sprawdzającej czy liczba mężczyzn jest > od liczby kobiet. Jeśli warunek jest spełniony należy przypisać „1”, a jeśli nie „0”.
- Dane według dziedzin→Stan ludności→Gęstość zaludnienia i wskaźniki. Tutaj należy powtórzyć procedurę opisaną powyżej, dodatkowo do pola wyboru dodać „Polska” (aby ustalić średnią gęstość zaludnienia). Bezpośrednio w Excelu w nowej kolumnie należy użyć formuły formatowania warunkowego „JEŻELI”, sprawdzającej, dla których gmin gęstość była < od średniej dla Polski. Jeśli warunek jest spełniony należy przypisać „1”, a jeśli nie „0”.
Efektem powyższych działań są trzy arkusze (tabele), które nie są równoliczne; to oznacza, że w niektórych gminach nie ma danych i nie da się wprost przekopiować danych z jednaj kolumny do drugiej. Wobec tego należy użyć formuły „WYSZUKAJ PIONOWO”. Do wybranej tabeli za pomocą tej formuły należy kolejno dodać wyniki z dwóch pozostałych tabel. W kolejnym kroku dla kolumn z wartościami „0” lub „1”, należy użyć formuły „JEŻELI”, sprawdzającej warunek gęstość*płeć*przyrost=1. Jeśli warunek jest spełniony należy przypisać „1”, a jeśli nie „0”. Uzyskane wyniki (325 gmin) należy posortować i podzielić na województwa pamiętając, że jego nazwę uzyskuje się z dwóch pierwszych cyfr kodu TERYT.
Zadanie nr 4
- Należy wyznaczyć punkty wspólnych obrysów budynków i linii widoczności z wykorzystaniem narzędzia Intersect (Analysis Tools→Overlay) z aktywną opcją Output Type (optoinal): POINT
- Wykorzystując punkty przecięcia należy rozdzielić linie narzędziem Split Line at Points (Data Management Tools→Features) z tolerancją 0,1m,
- Narzędziem Select by Location (Data Management Tools→Layers and Table Views) należy wybrać linie, które łączą się z punktem środkowym
- Należy dodać nowe pole (tyb: Double) i obliczyć długości wybranych linii.
Zadanie nr 5 (finał)
- Należy zagregować warstwę shp po nazwie makroregionu (Data Management Tools→Generalization→Dissolve). Wynik: kon_makro
- Uprościć warstwę Wisła_fragment.shp algorytmem Douglasa–Peuckera z parametrem tolerancji 500 m (Cartography Tools→Generalization→Simplify Line (Point_Remove) ). Wynik: wisła_frag_upr
- Utworzyć warstwę punktową z wierzchołków warstwy shp (Data Management Tools→Features→Features Vertices To Points). Wynik: wisla_pkt
- Przeciąć (Analysis Tools→Overlay→Intersect) warstwy wisla_pkt z kon_makro. Wynik: wisla_pkt_makro
- Obliczyć odległości, „strzałki”, punktów warstwy wisla_pkt_makro narzędziem Near (Analysis Tools → Proximity) do warstwy wisla_frag_upr
- W właściwościach warstwy wisla_pkt_makro w oknie Definition Query należy wskazać tylko punkty dla których odległości do warstwy wisla_frag_upr są większe od 0 m (z przyjętą dokładnością obliczeń!)
- Użyć narzędzia Summarize w tabeli zawartości warstwy wisla_pkt_makro dla pola MAKROREGIO, (Pole statystyk NEAR_DIST: Average). Wynik: zestawianie
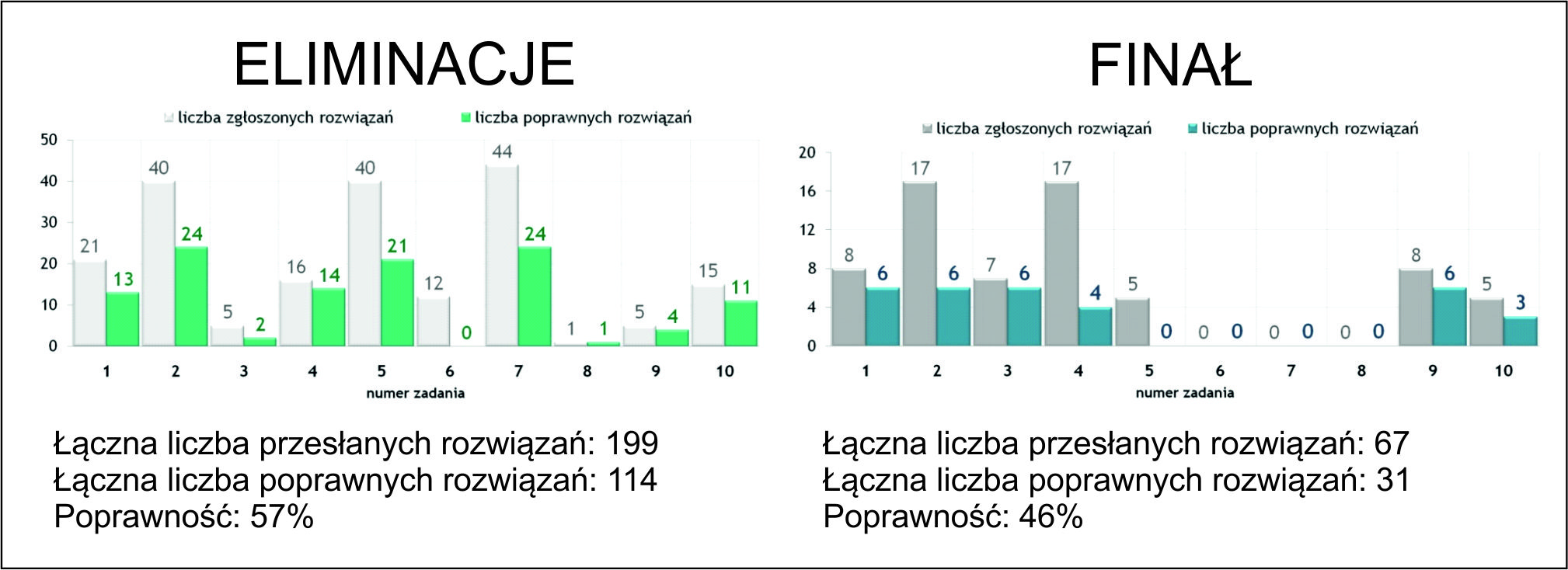
Ryc. 1. Zestawienie nadesłanych rozwiązań zadań w trakcie trwania GIS Challenge 2017
Szczegółowe informacje związane z opisem kolejnych zadań będą się pojawiać na stronie internetowej http://gischallenge.com/ i profilu Mistrzostw na Facebooku https://www.facebook.com/GIS-Challenge/.