
W ciągu ostatnich dwóch lat w Lublinie powstało 85 stacji Lubelskiego Roweru Miejskiego (LRM), a w przyszłości planuje się tworzenie kolejnych. Rowery LRM są intensywnie wykorzystywane przez mieszkańców Lublina, a świadczy o tym fakt, że w sezonie w roku 2016 roku odbyło się około 850 tysięcy przejazdów na wypożyczonych rowerach. LRM na bieżąco gromadzi dane dotyczące użytkowania swoich rowerów i wykorzystuje je do opracowania podstawowych statystyk, które można znaleźć pod adresem http://mirl.info.pl/s/statLRM. Jednak do tej pory nie powstała przestrzenna reprezentacja natężenia ruchu, obejmującego użytkowników systemu LRM, na poszczególnych odcinkach sieci komunikacyjnej Lublina w skali całego miasta. W niniejszym artykule zaprezentowano w jaki sposób, przy niewielkim nakładzie pracy, można stworzyć warstwę natężenia ruchu rowerowego z użyciem platformy ArcGIS oraz tabelarycznych baz danych.
Dane
Wykorzystane dane zawierają:
- warstwę dróg OpenStreetMap,
- tabelę opisującą wszystkie stacje LRM za pomocą nazwy, unikalnego identyfikatora oraz współrzędnych geograficznych
- tabelę zawierającą informacje o przejazdach rowerów, takie jak czas i miejsce wypożyczenia oraz czas i miejsce zwrotu roweru (Rys. 1.)
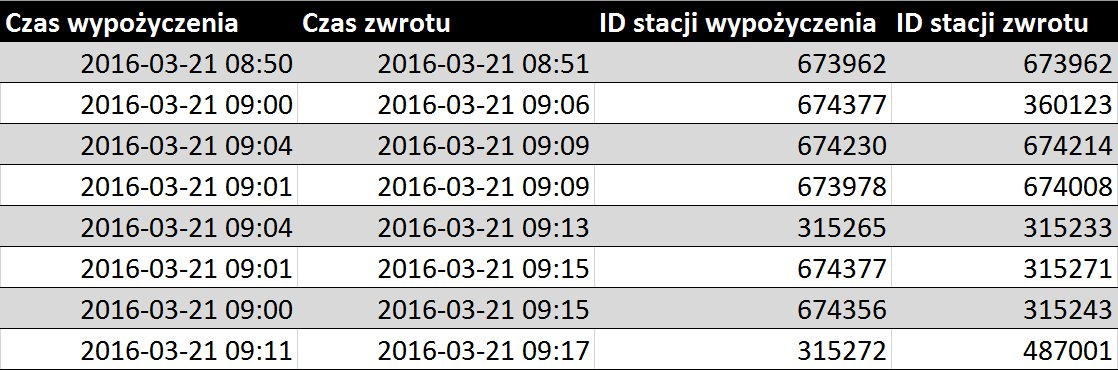
Rys. 1. Wybrane rekordy tabeli przejazdów.
Druga z wymienionych wyżej tabel została udostępniona na potrzeby projektu w postaci pliku .csv zawierającego wymienioną wyżej charakterystykę dla wszystkich przejazdów w obrębie systemu LRM w roku 2016. Odpowiednia agregacja tych danych dała w wyniku tabelę, która zawiera informacje o dokładnej liczbie przejazdów między każdą parą stacji. Następnie tę tabelę dołączono do wygenerowanej wcześniej warstwy, w której każde połączenie par stacji było reprezentowane jako linia prosta. W wyniku takiego działania otrzymano graficzną reprezentację ogólnych trendów dotyczących wykorzystania systemu LRM.
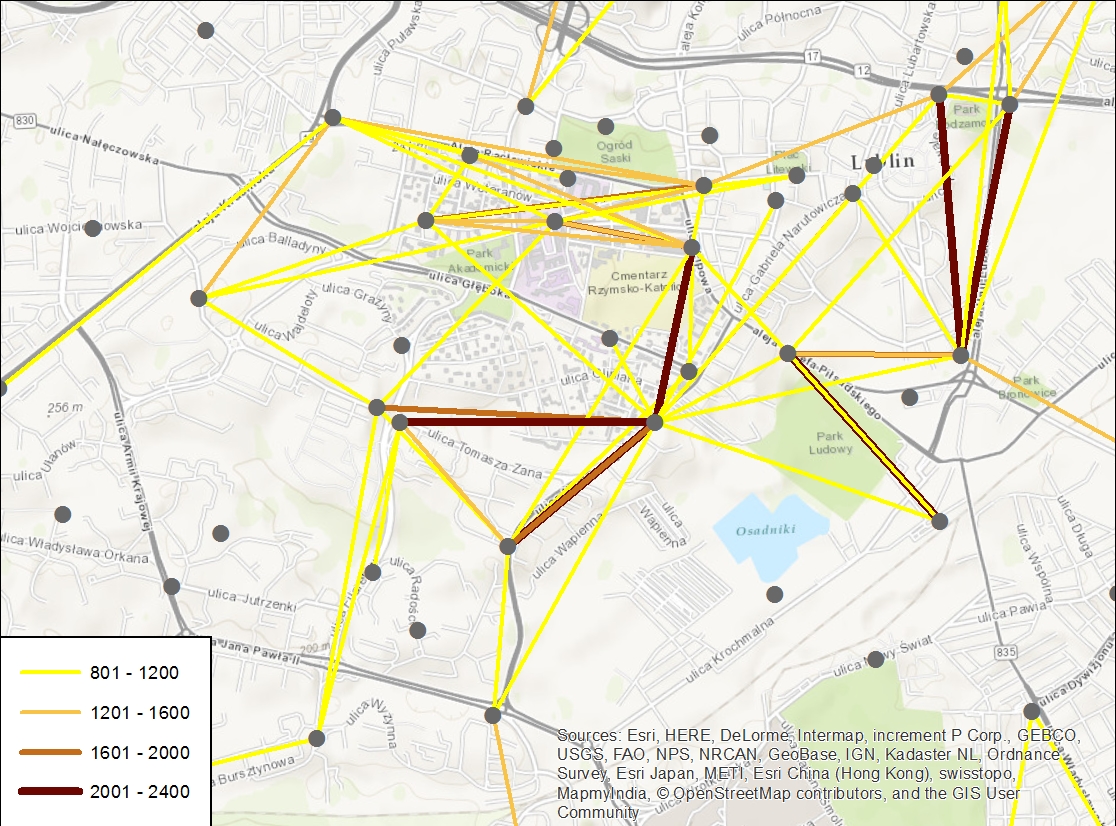
Rys. 2. Linie reprezentujące połączenia par stacji LRM wraz z informacją o łącznej liczbie przejazdów, centralna część Lublina.
Trasy przejazdów
Jeden wiersz w tabeli przejazdów opisuje zatem, między którą parą stacji poruszał się użytkownik LRM. Informacja ta umożliwia wyznaczenie najbardziej prawdopodobnej trasy przejazdu, czyli odcinków dróg, przez które przejechał dany użytkownik.
Jednym ze sposobów wyznaczenia wszystkich (ponad 7 tysięcy) tras jest użycie stworzonego specjalnie w tym celu modelu iteracyjnego, który według koncepcji przyjmuje warstwę linii, a zwraca wygenerowane trasy przebiegające między skrajnymi wierzchołkami każdego obiektu wejściowego.

Rys. 3. Model wyznaczania tras stworzony za pomocą ModelBuildera.
Network Analyst i dane sieciowe – Network Dataset
Do wyznaczenia tras wykorzystano rozszerzenie Network Analyst do oprogramowania ArcGIS.
Rozszerzenie to pozwala na wykonywanie skomplikowanych analiz na wektorowych sieciach komunikacyjnych, nazywanych w tym środowisku Network Dataset.
Opisany w artykule Network Dataset został zbudowany z wykorzystaniem darmowych danych OpenStreetMap, na które składają się szczegółowe informacje o drogach, chodnikach, ścieżkach rowerowych i tym podobnych. Jednak, aby takie dane mogły posłużyć do analiz związanych z ruchem rowerowym, wymagały one stosownego przetworzenia. Polegało ono między innymi na pogrupowaniu danych w odpowiednie klasy oraz nadaniu każdej z nich atrybutu hierarchi. Hierarchia odgrywa bardzo ważną rolę w trakcie wyznaczania tras – dzięki niej możemy decydować, które obiekty będą najchętniej wybierane przez algorytm.
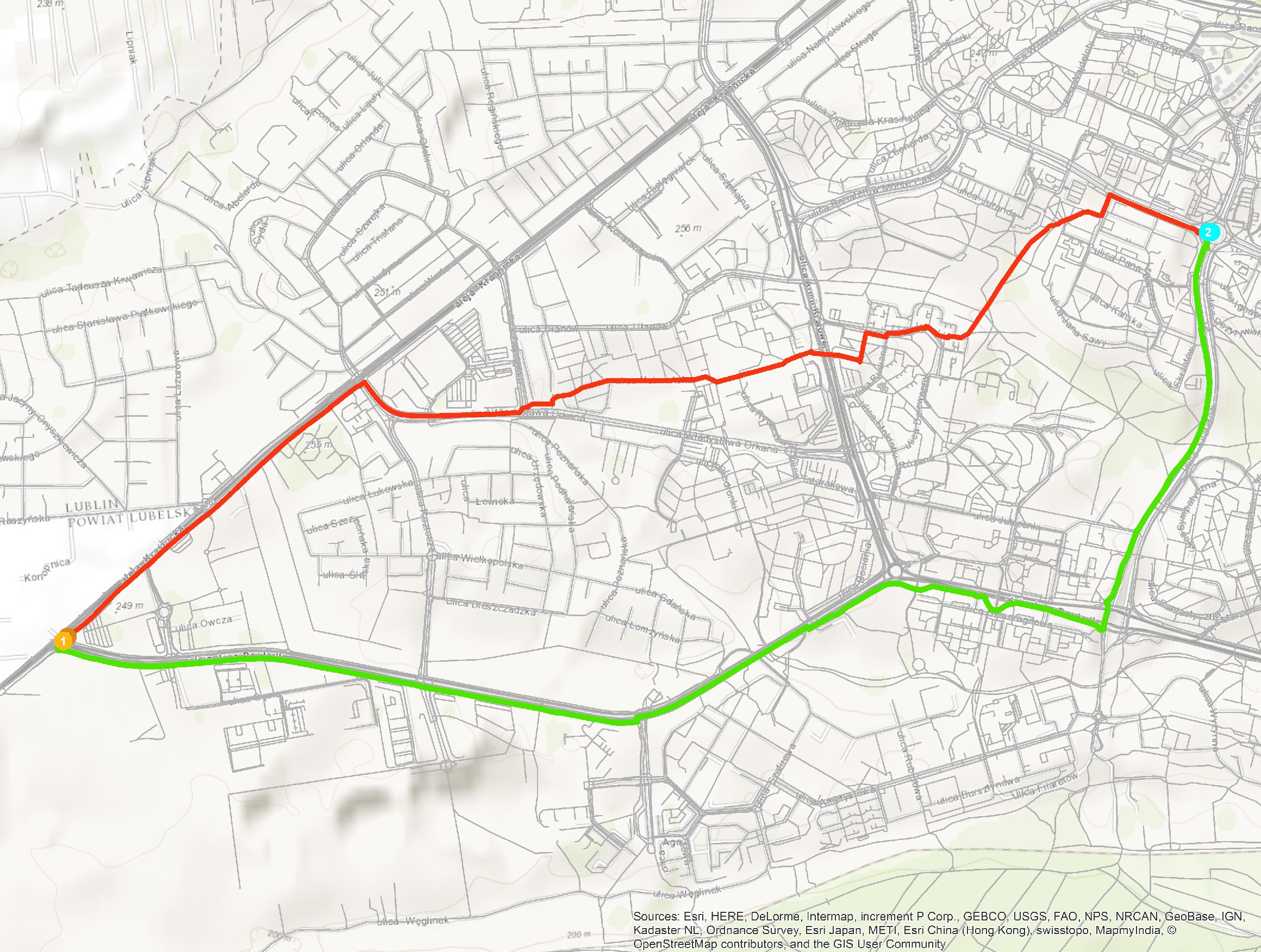
Rys. 4. Porównanie tras przebiegających między dwoma punktami na sieci bez hierarchii (czerwona) oraz z hierarchią (zielona). Trasa zielona w całości przebiega po ścieżce rowerowej.
Weryfikacja
Po pierwszym wykonaniu modelu (Rys. 3.) okazało się, że ponad połowa tras nie została wcale wygenerowana. Stało się tak ze względu na różne, często drobne i trudne do wychwycenia błędy topologii sieci, takie jak brak wspólnych węzłów między obiektami. Koniecznie było zbadanie i naprawienie wszystkich błędów.
Generalizacja sieci
Kolejnym problemem okazała się zbyt duża szczegółowość danych OpenStreetMap. Mimo, że pozwala ona wygenerować bardzo dokładne trasy, w przypadku, gdy tras było ponad siedem tysięcy, ich ogólny przebieg stał się bardzo chaotyczny i nieczytelny, przez co malało prawdopodobieństwo wyznaczenia poprawnego natężenia ruchu.
Trasy wygenerowane dla oryginalnej sieci miały w pewnych miejscach zbliżony, ale nie identyczny przebieg. Dlatego sieć dróg poddano znacznej generalizacji, zastępując na przykład wszystkie obiekty wchodzące w skład jakiegoś pasa drogowego jednym obiektem, który reprezentował całą ulicę.
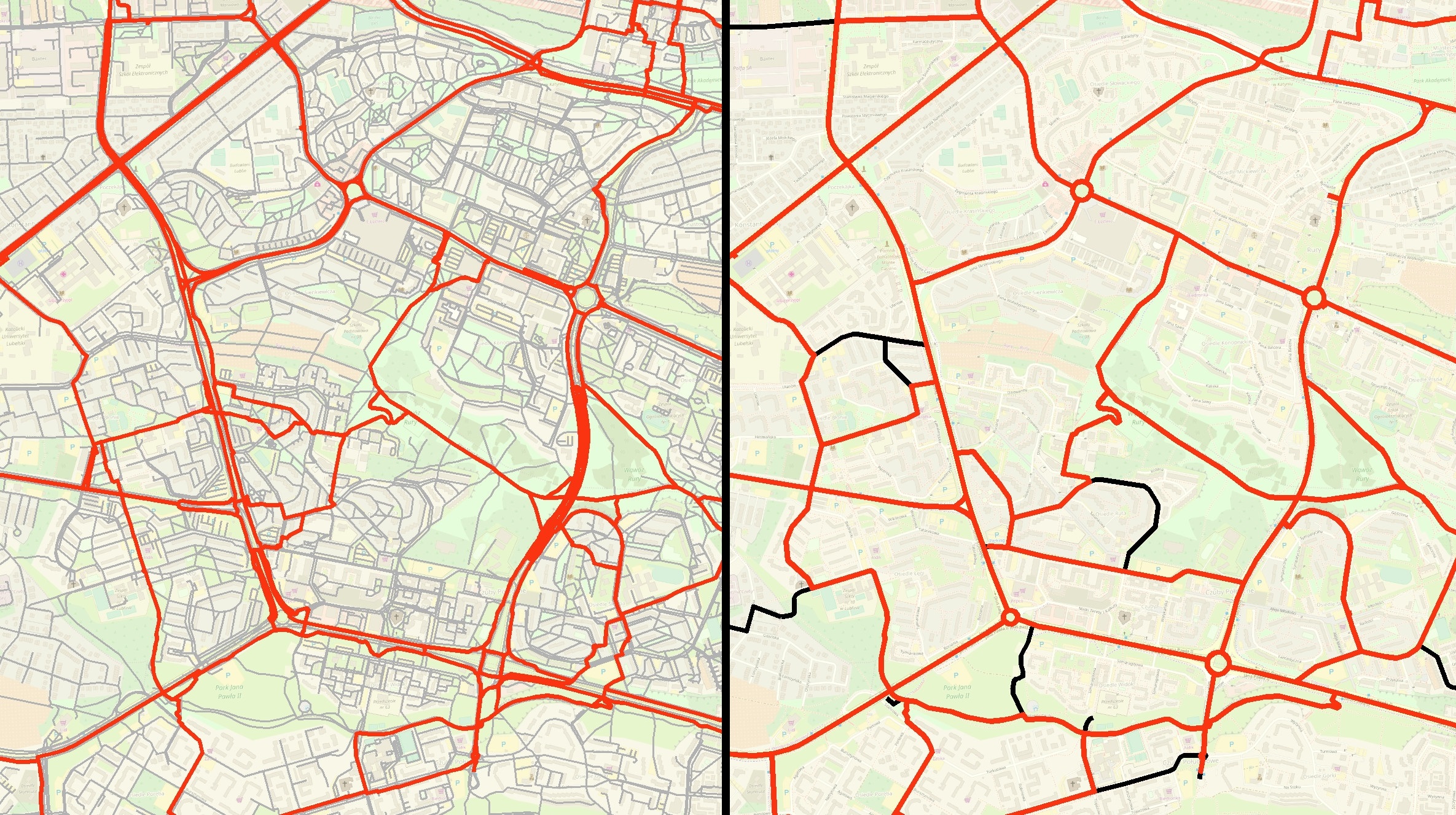
Rys. 5. Porównanie tras wygenerowanych na sieci przed generalizacją (po lewej) i po generalizacji (po prawej).
Po podjęciu wymienionych działań uzyskano przebieg wszystkich tras. Jednak taka warstwa nadal nie przedstawiała właściwego natężenia ruchu. Wynikało to stąd, że jeżeli w pewnym miejscu (odcinku drogi) jakieś trasy mają identyczny przebieg (nakładają się), wówczas nie istnieje jednoznaczna informacja o tym, ile rowerów miejskich przejechało przez takie miejsce.
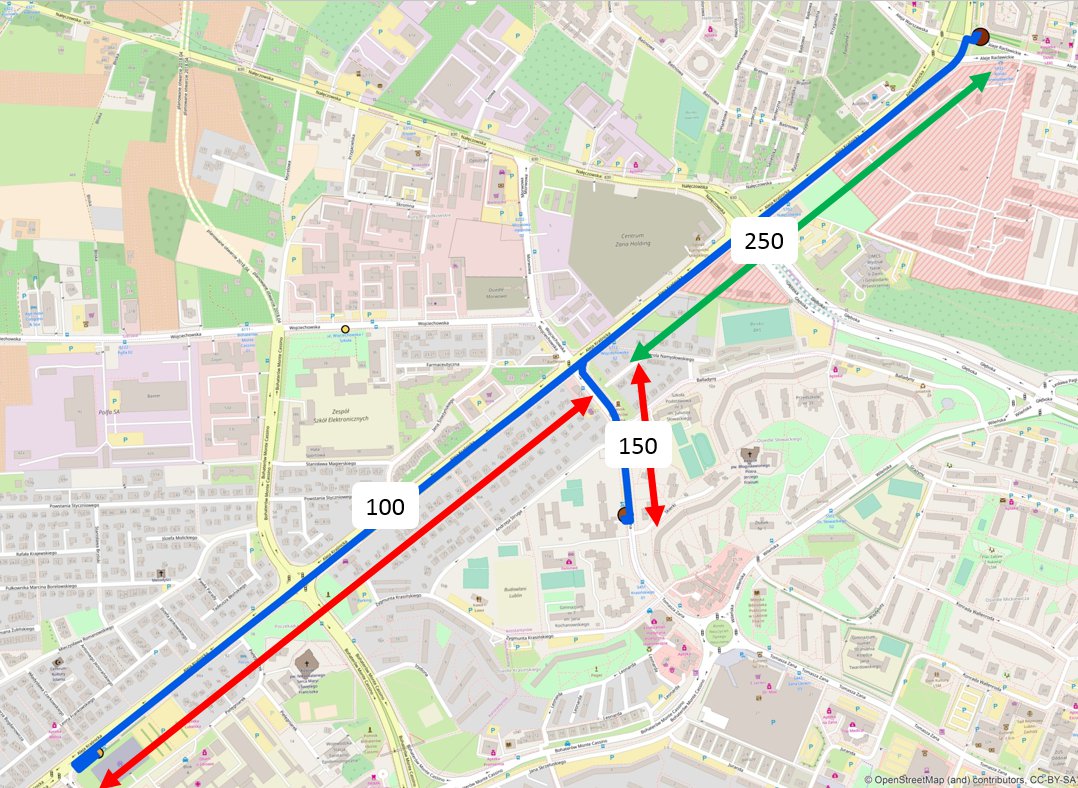
Rys. 6. Sytuacja, w której trasy mają częściowo wspólny przebieg – warstwa nie zawiera informacji o łącznej liczbie przejazdów na zielonym fragmencie.
Aby taką informację uzyskać, należało wykonać złączenie przestrzenne warstwy tras i warstwy dróg, według zasady, że jeśli jakaś trasa X przebiega przez pewien odcinek drogi, to przez ten odcinek przejechało dokładnie tyle samo rowerzystów, co przez całą trasę X.
W wyniku takiego złączenia otrzymano warstwę, w której każdy odcinek sieci jest opisywany przez dwa atrybuty: łączną liczbę użytkowników LRM, która przejechała przez ten odcinek, oraz liczbę tras, które przebiegają przez ten odcinek. Jest to zatem warstwa natężenia ruchu.
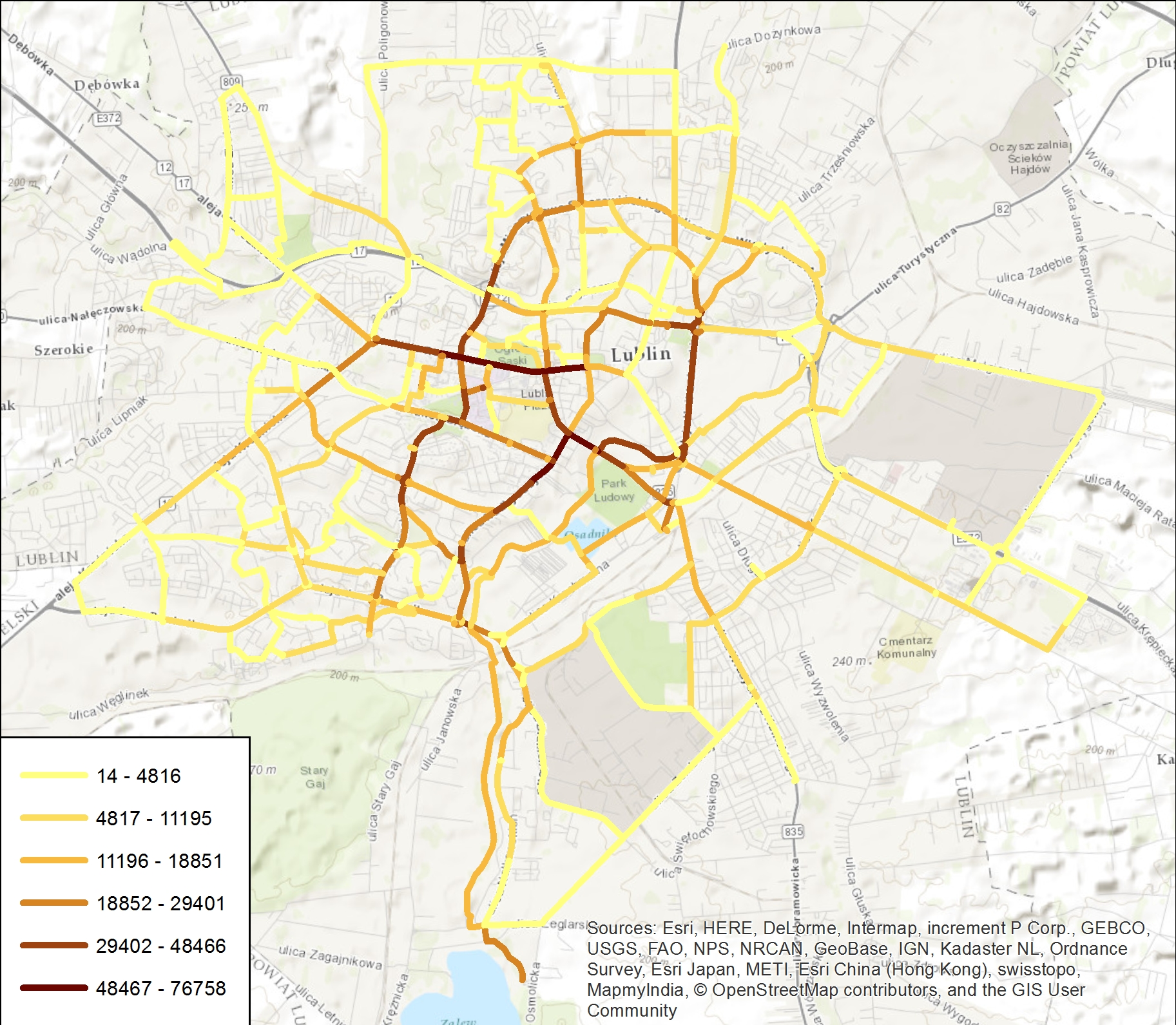
Rys. 7. Warstwa, w której każdy odcinek dróg jest opisany przez łączną liczbę użytkowników LRM poruszających się na nim w sezonie roku 2016.
Podsumowując: przyjmując odpowiednie założenia, postępując według dobrze opracowanej procedury oraz działając na poprawnej geometrycznie sieci dróg można wygenerować warstwę natężenia ruchu bazując na danych tabelarycznych, które opisują początek i koniec bliżej nieokreślonej trasy. Rozbudowane narzędzia platformy ArcGIS pozwoliły, by wspomniana warstwa natężenia ruchu szczegółowo i przestrzennie przedstawiała sposób, w jaki wykorzystywany jest system Lubelskiego Roweru Miejskiego.